This is cramazing. If you need some white noise to code to, this is as nerdy-awesome as you’re gonna get. Kudos to Shawn Blanc for finding it.

This is a darn useful control for iOS. Gotta love open source, amirite?
Warning: what you are about to see will offend your sensibilities as an engineer. It should never be used in production or for user-facing or critical client purposes. It is terrible, no-good very-bad hackiness, and also kinda works. I just hope there’s not some simple way to solve this that I totally missed. Now that you’ve been warned, read on!
There’s a problem with Rails page caching – the page has to fully load once in somebody’s browser before the cache kicks in. That means somebody’s request is really slow, or worse, times out. Not so good. Wouldn’t it be nice if something in the background could do all of a page’s data operations, render the view, and then update the cache for that page, without users ever noticing? Well, check this out.
You can render a page in irb via this method:
app.get 'https://www.mywebsite.com/slow/endpoint'; true
response = app.response; true
I use ; true to prevent irb from dumping huge amounts of request / response data onto the console.
Unfortunately, I couldn’t find any way of doing this outside irb that wasn’t very complicated. Our slow endpoint was on a back-end administrative page only; faking the session data in curl would have been annoying. Also, it was exceeding the timeout limits of our production server. So I had to add an ugly line in: Admin::SlowController.set_timeout 60000, which has to be run in the rails environment. So, irb it is! Or script/console in this case.
Here’s the rundown. I set up a shell script cache_generator.sh to run irb with a ruby file, like so:
#!/bin/bash
script/console production <worker/cache_page.rb
Then set up a ruby script cache_page.rb to do some crazy duck-typing to prepare our environment, render the page, and stuff it in Redis (our cache of choice):
Admin::SlowController.skip_before_filter :admin_required, :only => [:long]
Admin::SlowController.set_timeout 60000
app.get 'https://www.heyzap.com/admin/slow/long?ignore_cache=true'; true
response = app.response; true
REDIS.hset('page_caches', 'long', response.body)
This ignores the required filters, runs as long as it needs to, renders the page and stores it. Now all that’s left is to display it. In our controller method, I just added the following at the top:
def long
# don't use cache
if page = REDIS.hget('installs_cache', 'main') & !params[:ignore_cache]
render :inline => page and return
end
# ...
render :action => :long
end
That render :action => :long at the end is important - that’s necessary for the script/console code to work correctly. You might also want to skip the cache if there’s a fancy query string or something - maybe if params.count > 2, so if there are any crazy options the option-less cache won’t be used.
Last step, set up a cron job to run your script every now and then. I set ours for every five minutes, so we won’t be too far off real data.
*/5 * * * * cd /home/deploy/myapp/current && worker/cache_generator.sh
And boom! Your page now re-generates regularly, and is cached whenever users actually hit it. Wacky, hacky, and fun!
Also helps if users can change their ids - doing so would break paperclips attachment scheme under normal circumstances.
Pretty simple, pretty reliable. if for some reason you need to leave mass-assignment on a model. Like, say, if you use Devise
Looks like brew install imagemagick didn’t work for me. Found a bunch of people having issues after they moved the repo for it, but that wasn’t my problem. My problem was that it was refusing to create symlinks in /usr/local/etc. Seems /usr/local was owned by admin and set to 0775, and /usr/local/etc was also owned by admin and set to 0755. Temporarily chmodding these folders to 0777 fixed it, then I put everything back the way I found it.
Guess Homebrew ain’t always perfect.
It has a plugin to automatically type “bundle exec” for you when appropriate. See here
Neat, huh?
One of the things I really miss about using a hosted, web-based blogging service like Tumblr or Posterous was the bookmarklets - a javascript bookmark that would quickly create a new post out of whatever I had highlighted. Since there’s no easy way to get from javascript to filesystem commands (even for Chrome extensions and the like), I decided to write a little script to do it for me and link it to a system-wide service. Here’s how you can use it, too.
First, in your jekyll project directory, make a file called new and copy it from this Github gist. For easy mode: download the gist here.
From the command line in your project directory, you can call it with a title, image, or link, like so: ./new "A new post title". The script will figure it out, make a new page out of it, and open it in TextMate.
To call that from anywhere, we’ll need a service. Pop open Automator and select “Service” from the dialogue that comes up, like so:
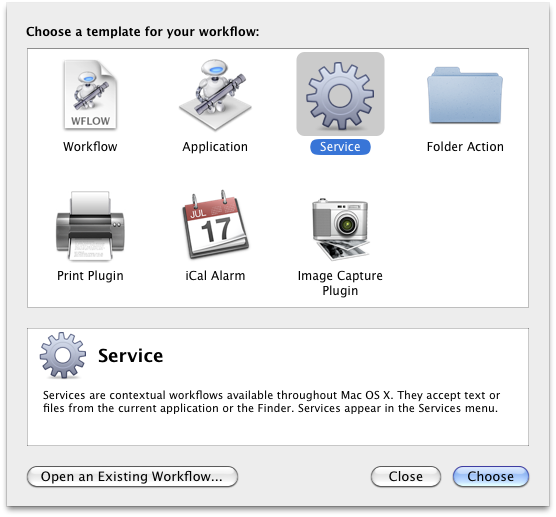
Then, choose “get selected text” and send it to the “run a script” action, pointing it to your new script, like so:
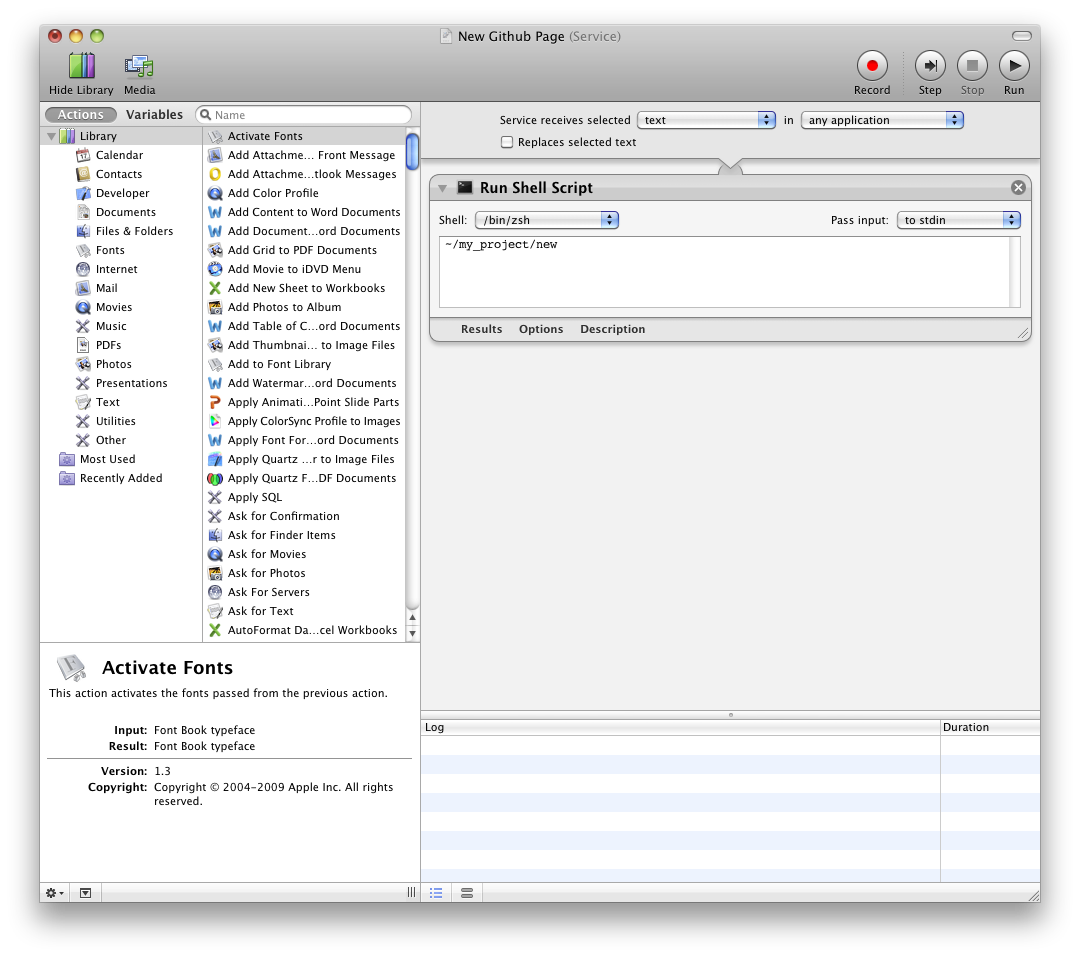
Save the service as something appropriate. I called mine “New Github Page”.
To make this even easier, add a keyboard shortcut for your new service. Go to the “Keyboard Shortcuts” preference pane, select “Services” and find the service you just made in automator. Double-click to the right of the service name, and choose a good global hotkey. I chose CMD+ALT+G, since “command alt Github” is easy for me to remember.
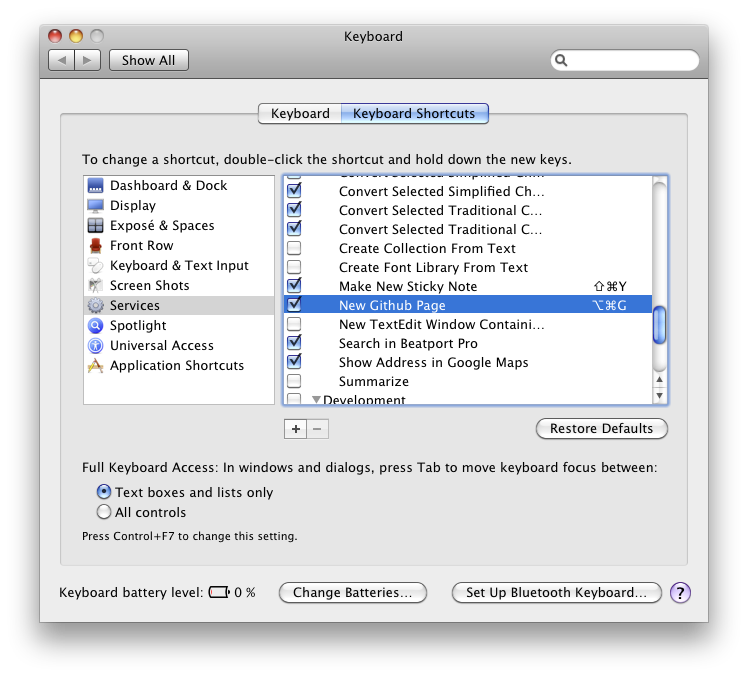
Now, from any page, you can select the url (hopefully with CMD+L or some other shortcut) and hit your “new page” key, and it will make a new markdown file with the page’s Title and a custom permalink, and whatever default layout you want. Or select an image and quickly get the image downloaded and linked in.
It’s super easy. If you have any suggested improvements, feel free to fork / edit the Github gist, leave comments, etc. Hope this helps somebody!
Run IE 7, IE8, & IE9 Free in a Virtual Machine
This is great. Man, I wish I had had this six or seven years ago.
I was reading this article from Mark Cuban, and honestly I don’t quite understand what it’s about, but here’s a question:
What if patents were granted with a stipulation: they must be licensable on a percentage-of-profits basis with some reasonable maximum. Say 30%, like Apple is taking for app store sales.
This would mean that we could still get patents for valuable technology that would guarantee wealth for the original inventors, but allow any startup a fair shot at profiting from them as well. We could also add a non-stacking resolution for it: if I’m building off thirty Microsoft patents, they’re still entitled only to 30% of my profits. If Microsft, Apple, and Google all want to sue me, I must be doing something right. They can all split the 30%. This would also cause dramatically different ROI calculations on the kind of litigation used to enforce these sorts of patents.
Ultimately, it may not be possible to make patents work in the lightspeed technology industry. But maybe this would be a better and more palatable compromise than what we have now.